我所了解的编辑器
引言
约六年多前,笔者初入前端,在大四时成为一名前端实习切图仔。彼时的前端,正在发生翻天覆地的变化:前端框架,React、Vue正攻城略地,步步蚕食jQuery的领土;前端工程化,Gulp/Grunt还没站稳脚尖,又面对着Webpack滔天的洪水;大前端的概念兴起,从不忌讳地表达其一统所有前端设备端的野心。新技术此起彼伏,令人眼花缭乱,又让人深感不安。每个新人,既希望在大变革之际,乘风破浪,一往无前,又害怕卷入乱流,搁浅前滩。
当时,对前端规划的主流观点:”3年内入门熟练,而后选择细分方向,深入巩固,形成自己的护城河“。而当时有哪些细分方向?几经求索,在知乎大佬的指点下,总结为:内核、富文本、可视化、工程化(当然,如今细分领域更是百花齐放)。可能大佬们也想不到,当年或许随意的几句话,便化成了笔者六年的时光。实习一年,毕业后两年,一心切图,而后机缘巧合下到金山从事新的Web富文本/排版软件开发,后至今日头条,围绕图文创作开展工作,在领域内已三年有余。其实三年的时光,以十年为度量的细分专业领域,显得微不足道,所以笔者在提笔时诚惶诚恐,生怕表述有误,贻笑大方;但又念在自己仍保留一丝世一大的浩然之气,师承WPS,背靠头条,两三口康师傅茉莉花茶下肚壮胆,心一横,便厚脸皮写下此篇“富文本”的介绍类文章,为各位同仁提供一丝经验或思路。
如有谬误,敬请指正。
编辑器模块划分
从个人视角出发,编辑器可分为四层抽象:分别为「数据」、「排版」、「渲染」、「交互」。
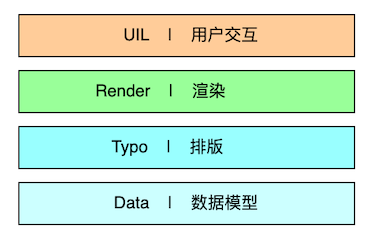
数据
数据,大概分为两方面,其一,是指源文件和内存数据结构的相互转化,主要的步骤有:读取、解析、结构化、以及对应的逆运算;其二,是指发生编辑行为时,内存数据结构变化的过程,便是常见的增、删、改、查。
读取解析
虽源文件类型各异,但万变不离其宗,读取解析,基本就覆盖了编译原理的主要步骤。当然,常见的编辑器作为应用层,一般不涉及更底层的硬件优化,往往得到语法树后,便可代表解析的结束。
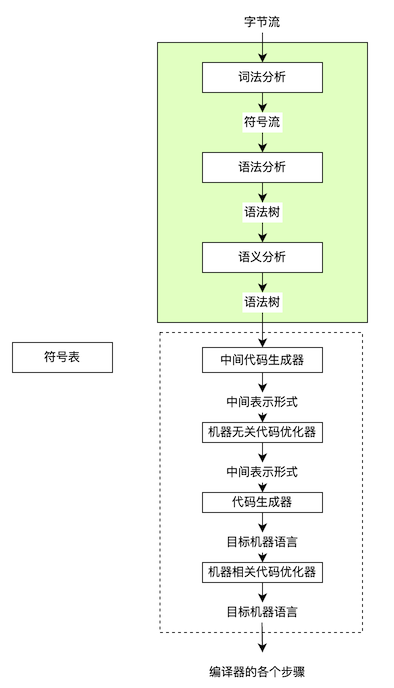
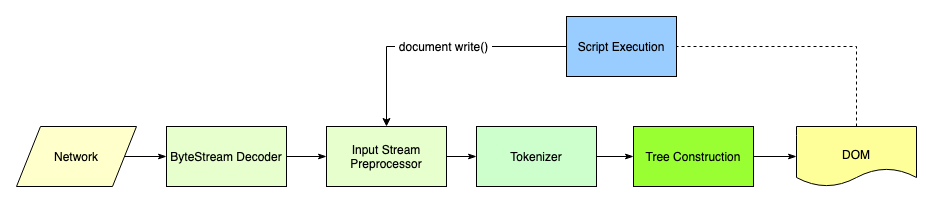
比如,HTML的解析步骤,基本也能和以上步骤所对应,此链接有更具体的实现细节:
内存数据结构及其变化
在接触的项目中,对数据的操作往往是通过类索引(index)的方式进行。外部视觉看,富文本如同一维数组,每项内容代表一个带格式的节点。这种方式的好处:非常直观。
// 操作对象:字节跳动 |
但具体实现则不然。
出于性能考虑,需要引入“区间”(range)概念,使数据更紧凑。
[{ |
另一方面,会引入“偏移”(offset)概念,其原因是在修改数据时,更新某一个区间不会导致所有区间雪崩式变动。
// 比如每个区间的start,可能指的是相对前一区间的偏移量 |
为了兼顾增删改查,一种通用的方法是确定某种大小关系,以此构建红黑树(理想情况下,增删改查均为O(log(n))的平衡二叉树),再针对高频操作或瓶颈加以优化。这是在前司学到的技巧,在 VS Code 的 Text Buffer Reimplementation 优化中也有类似的概念。
排版
排版,可约等于数据在空间的排列方式。
影响排版的要素有二,其一是元素的自身属性,另一个则是应用的排版规则。对比极其考虑计算机基础的数据层,排版则更多和“业务”(比如不同的排版标准)相结合。
富文本编辑器中的「富」,狭义指的是多格式的图文,广义则指一切能在前端设备展示的元素,可以是图片或文字,也可以超链接,视频,文件,乃至各种内联应用。
元素
前端最常打交道的便是图片和文字。但应注意,因为浏览器要考虑跨平台性,文字或图片能应用的Css样式,往往已经是抽象或阉割后的属性。比如字体,脱离Css,可以找到更进一步的描述:FreeType;而对于图片,不同图片也存在差异的(PNG、JPEG)。在个别场合,图片在Web端和其它端上表现不一致,便可能是某些被阉割的属性在起作用。
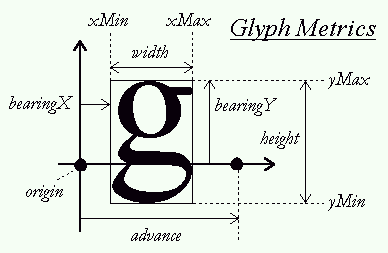
排版规则
排版规则极其复杂。前端熟悉的盒子模型、弹性布局便是不同的排版规则。显而易见,相同元素在不同排版规则下的表现是不同的。有趣的是,在字体内部,也有着各种繁琐的规则。比如:因为字距对(Kerning pairs)属性,VA 和 V、A 所占空间是不同的。文字内排版规则,也常和语种关联。比如涉及到阿拉伯语时,字体会发生“形变”:ب س ب ب 和 بسبب是相同的;而当ltr(从左到右)和rtl(从右到左)文字相结合时,又会涉及 Bidi 双向算法。
遗憾的是,笔者未能深入实现某个排版规则,仅在此列举一二。
渲染
「数据」经过「排版」处理后,将得到的具体元素位置信息提交到前端设备的过程,便是「渲染」。
基础优化
在笔者接触的工作内容中,富文本中的“渲染”要比图形学中的“渲染”简单很多。在富文本的渲染中,会强调调度(scheduler)和层级(layer),也注重可视区(Viewport)。这基本上和一些人机交互经验有关,在性能吃紧的场合,会优先渲染可视区范围内重要层级的内容,而推迟可视区外、或不重要的内容,也即是分块、分阶段渲染。
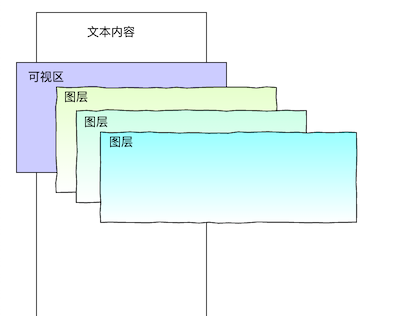
而优化渲染模块时,会感到某些技巧似曾相识。比如:计算和提交两者分开(类比React中的render和commit两个概念),有助于保留「空间换时间」的可能,尽可能提前处理耗时操作,从而实现诸如离线渲染,双缓冲等策略(预烘焙?),避免白屏时间过长。
字体回落
当然,也接触一些新颖的概念,比如:“字体回退(Font Fallbacks)”。由于版权等限制,在涉及某些商用字体的情况下,编辑器会有回退策略,从列表中返回相似的字体,类似于Css中的font-family: sans-serif, '微软雅黑' 。Emoji作为特殊的字体,因存在平台差异,也需要有对应的回退。
交互
交互层面,则是大多数前端工程师所熟悉的领域了。交互可分为两方面,一方面指和编辑器的互动(编辑文字、图片等),另一方面则是等通常意义的前端组件(工具栏,侧边栏等,和编辑器互动性较弱)。
常规流程
一个完整的编辑流程,通常由交互触发(比如输入、拖拽等),进而修改数据,触发排版,最后通知渲染器进行渲染刷新。

对应Web前端,可以是大家熟悉的步骤:JavaScript(调用Api变更数据) -> 触发排版 (Style、Layout) -> 通知渲染(Paint、Composite)。因为排版引擎是浏览器的重要组成部分,当然不会缺少这些抽象。

在此还有一个有趣的概念:点击测试(Hittest)。可以简单认为其为一个纯函数,入参屏幕坐标(x,y),返回结果为当前坐标的数据上下文(比如索引、节点、格式等)。
点击测试
通过点击测试,能有效建立交互和数据、排版的通道,从而实现各种自定义交互。(比如:模拟 Hover 效果:通过监听鼠标移动,检索当前鼠标坐标是否和某个文本元素碰撞,如果碰撞,即认为发生 Hover 行为)。这种方式能突破通常意义的前端限制,比如允许不受层次限制(后续更新:不建议过于特立独行,在飞书写排版渲染框架时,发现很多看似很傻的Web标准,都是有深层次原因的),也可以在其它载体(比如 Web 端的 Canvas )模拟熟悉的交互行为(比如自定义光标和选区)。一个简单的点击测试前端实现:对有序的排版数据做二分查找,再顺序遍历无序元素(比如浮动元素)。
当编辑器遇上Web
「数据」+「排版」+「渲染」+「交互」,构成了一个平台无关的富文本编辑器实现。但其复杂程度也往往让人望而却步。
所幸的是,Web的蓬勃发展降低了实现富文本编辑器的难度,驾驭HTML + CSS + JS 三剑客的浏览器,在极大程度上,屏蔽了数据、排版、渲染上的实现难度,使开发者能将更多的精力聚焦在「交互」细节上。这里面有好有坏,下面稍以展开。
等级(伪)
在Web富文本领域,有一个相对通用的等级:
- Lv0:
Input / TextArea+document.execCommand - Lv1:
contenteditable+observerable+parser - Lv2:自排(指排版
layout) + 自绘(指渲染render)
Lv0 级别的编辑器,在表现形式和兼容性上存在非常大的局限,更多是作为一些表单组件使用。
Lv1 级别的编辑器(多数开源的富文本都是这种实现方式),在监听DOM变化时,通过语法模型约束修正,能较大程度实现编辑行为的相对统一,但对一些非标准化的行为(比如光标、选区),在不同的浏览器上会存在各种细微的差别或Bug。

Lv2的编辑器(多数商业软件,比如WebOffice、谷歌文档、Office365、飞书文档3.0等),出于性能和自定义能力,会抛弃HTML + CSS,转而实现自身的排版和渲染。Lv2的编辑器,具有更高层次的灵活度和一致性。
整体对比如下:
| 优点 | 缺点 | |
|---|---|---|
| Lv0 | 灰常简单 | 干啥啥不行,吃饭第一名 |
| Lv1 | 1. Css的表现方式已经足够灵活 2. 流畅程度整体优于Lv2编辑器(此点略反直觉,下面论述) 3. 学习成本较低 |
1. 在非Web标准上,如:选区光标,缺乏一致性。 2. 难以实现Css不支持的效果(或者需要额外的JS辅助,变相实现了自定义排版),比如:文字环绕图片。 |
| Lv2 | 1. 非常灵活 2. 可优化空间大 |
1. 任何细小功能,都需要考虑前端、排版、渲染、交互各层次时间,研发成本过高 2. 自成体系,对现有前端集成能力较差。比如,很难基于 OOXML (DOCX 的源格式)的排版软件上,实现类 Notion 的产品 |
在行业技术鄙视链触发,Lv2 > Lv1 > Lv0。但这只是从技术角度出发,而不代表产品的好坏。毕竟,绝大多数产品,是以需求,而不是技术为导向。“百姓喜闻乐见的事情,程序员算老几”,“存在,即意义”。
经验之谈
笔者曾有幸参与后两种编辑器的研发,因此有一个不成熟的观点:“在非专业商用场合,一个以兼顾用户体验、开发进度为目的 Web 富文本编辑器,Lv1 > Lv2。”。我的基本观点是:
- 构建于 Html 之上的编辑器,学习成本相对平顺,研发和维护成本要较低。
- 非极端场景,Lv1的性能体验要优于Lv2的性能体验。
反直觉论述:作为核心驱动要素之一:「性能」的Lv2编辑器,在整体(指的是整体体验,而不是某个方面)流畅程度上要稍逊于Lv1:
现代型浏览器对性能的压榨和各种奇淫巧技的运用已经到了令人发指的地步(可通过V8博客窥探一二),断不是单线程的Js、或缩水版多线程(指 WebWorker )所能比拟的。比如,基于现有的技术条件,前端的Schedule调度是通过
requestAnimatie | requestIdleCallback | setTImeout模拟的。Web编辑器沉淀时间尚短,商用的Web编辑器(Web 2.0的见证者),是最近几年发展起来的,和浏览器还处于磨合期。比如:开发人员的质量有待提高。非常尴尬,大部分前端开发人员不熟悉编辑器,而熟悉编辑器的前辈,却不熟悉前端。
因此:如果团队不具备编辑器相关的深厚研发能力,Lv1 级别的 Web 富文本编辑器是不二选择。
Prosemirror
在此安利下 Prosemirror 框架,作者 Marijn Haverbeke,同时也是 CodeMirror、acorn、lezer 的作者,已经在 Web 编辑器领域沉浸了十多年,目前作为独立的软件开发者,在开源社区中非常活跃。

Prosemirror 是一款优秀的框架,实现了编辑器的基本特性,清晰的语法解析支持,完备的事务系统,甚至支持多人协作等。
但与其它富文本组件不同,Prosemirror 定位更像是一个编辑器的骨架,而不是一个完备的编辑器。这意味着,开发者可以基于这个骨架,灵活地实现形态各异的编辑器。既可以类UEditor 这样的富文本,也可以是类 Notion 的协作工作台,或者是类秀米那样的图文排版工具。如果开发者对编辑器的有强烈的定制化要求,Prosemirror 不逞多让。
但在使用的过程中,Prosemirror 也有比较明显的弊端。一方面该框架由外国大神编写,仅包含少量的英文示例和相对晦涩的 API,同时编辑器也是相对小众的领域,从而导致中文文档匮乏;另一方面,Prosemirror 的规划更偏向于扩展性骨架,无法即插即用(作者原话:The core library is not an easy drop-in component—we are prioritizing modularity and customizability over simplicity),导致采用Prosemirror 的学习和使用成本要比其它框架陡峭,劝退了一部分开发者。
广告时间
P.S. 本文是知识分享类文章,不是带货类文章。不要因为广告时间,而否定上诉知识或经验。
那么,是否有某种框架,既能最大限度保留 Prosemirror 的拓展性,又能提供各种插件,以即插即用呢?Syllepsis 了解一下。
Syllepsis 诞生于头条号,初衷是服务于专业作者创作的富文档编辑器,后延伸到其它部门,其内部版 syl-editor 已被今日头条、西瓜视频、幸福里、懂车帝等超过30+的部门打磨使用。可以简单认为,Syllepsis 是建立在 Prosemirror 基础上的 React 组件(曾经也有Vue版本,但由于种种原因,比如:字节喜欢招Vue的研发进来写React,如今仅保留接口实现),其目的只有两个:
- 提供常见的编辑插件,更简洁的接口,保证开箱可用,简单可配置。
- 保留 Prosemirror 易拓展的特性,在现有插件无法满足需求时,仍保留定制的能力。
当然,该项目在开源方面还在起步阶段,你可通过文档进一步了解 Syllepsis 的能力。笔者认为,构造一个活跃的生态才是开源项目能源远流长的核心要素,欢迎所有同学在 Issue 上畅所欲言,反馈 Bug,提供对富文本编辑器的见解或需求。
结语
编辑器其实是一个非常复杂的模块,单凭个人难以实现所有的内容。笔者也只是在各前辈积累的基础上,结合自身的工作内容,讲述自己的见解。限于篇幅和能力,很多地方只是一笔带过,欢迎同行勘察和补充。最后,感谢 WPS 的烈锦同学,阿里的小海豹同学提供写作灵感和修改建议。